前回で、Nagiosサーバのセットアップは出来ました。 今回は、サーバから、外部システムの監視を考えてみたいと思います。

外部システム=サーバやルータなど、の監視対象をまとめてノードと呼ぶことにします。ノードの各監視項目ですか、大きく分けて二種類になります。
外部から監視できるpingやhttpサービスの監視と外部から監視できない負荷やディスク容量など内部の監視です。
まず前者の外部からの監視を設定します。
Nagiosの設定ファイルに関して
Nagiosの設定は、グループ化やテンプレートなど、簡潔に設定できるようになっていますが、構造を理解する必要があります。 またGUIでは設定ではなくテキストベースでの編集になります。
Nagiosサーバから外部監視
Nagiosサーバでの設定
Nagiosサーバからsshポートが空いているかチェックするだけのシンプルな監視ですが、通知先や、ホスト、ホストのグループなどいくつか設定が必要です。
設定が長い気もしますが、将来的にノードを追加していくときに既にある設定を継承したり、グループ化したりできるので、結果的に管理がしやすくなります。
# cd /usr/local/nagios/etc/
# vi nagios.cfg
---以下の行のコメントを外しておきます。
cfg_dir=/usr/local/nagios/etc/servers
---
# mkdir /usr/local/nagios/etc/servers
# cd /usr/local/nagios/etc/servers
今回テスト的に設定する監視対象のファイル
# vi test_node.cfg
###############################################################################
# CONTACT GROUPS
###############################################################################
define contactgroup{
contactgroup_name test_node_contact
alias test_node_contact
members nagiosadmin
}
###############################################################################
# hosts
###############################################################################
define host{
name test_linux-server
use linux-server
notification_period 24x7
contact_groups test_node_contact
}
###############################################################################
# hosts
###############################################################################
define host{
use test_linux-server
host_name testnode.jp
alias test_linux-server
address [ノードのIPアドレス]
}
###############################################################################
# Hostgroups
###############################################################################
define hostgroup{
hostgroup_name test node
alias test node
members testnode.jp
}
###############################################################################
# service
###############################################################################
define service{
name server-test-service
use generic-service
contact_groups test_node_contact
}
###############################################################################
# Services Common
###############################################################################
define service{
use server-test-service
host_name testnode.jp
service_description check_ssh
check_command check_ssh
}
---
設定ファイルに不整合がないかチェック
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
問題無ければnagiosサーバを再起動します。
# service nagios restart
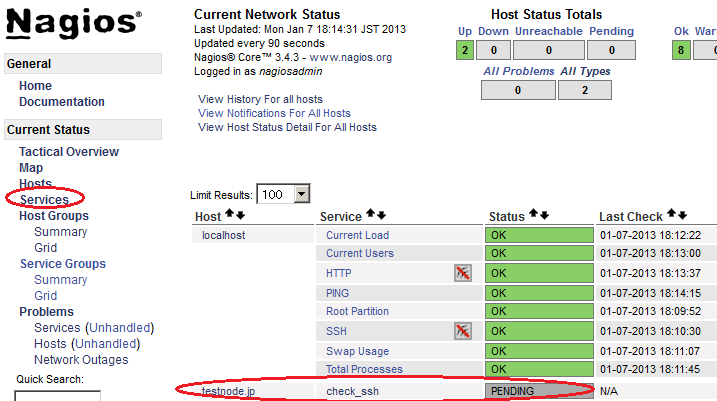
Servicesをクリックして一覧を見てみるとこのように監視対象が一つ追加できています。
ノード内部の監視(NRPE)
ノード内部でしか取得できない値の監視には、Linux系の場合NRPE(Nagios Remote Plugin Executor)というプラグインを監視対象(ノード)にインストールしてこれを経由して取得するものが用意されています
これはTCP port 5666を使いますポート制限の設定が必要になる場合があります(暗号化はデフォルトでONになっています)。 また、サーバと監視対象の両方でviやemacsで設定ファイルを編集する必要があります。 若干煩雑ではありますが、設定を全てテキストベースで行えるので監視対象が多くなっても手早く確実に監視設定ができるようになります。ただし設定箇所が分かれるので正しく監視できるまで段階的に追っていきたいと思います。
監視対象でNRPEをセット
インストール
ノードのNRPEはyum(epeoリポジトリなど)でインストールできます。
# yum install nagios-nrpe
併せてNagiosのプラグインも一通りインストールします。
# yum install nagios-plugins-all
これで一気に入ると楽ですが、依存関係などで失敗する場合、以下のように一つ一つプラグインを入れていきます。
# yum install nagios-plugins-users
# yum install nagios-plugins-load
# yum install nagios-plugins-disk
# yum install nagios-plugins-swap
# yum install nagios-plugins-ntp
テスト
まず、ノード内で監視をテストしてみましょう。
# cat /etc/nagios/nrpe.cfg
などをして中に書いてある
command[check_load]=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
をノードのコマンドラインでテスト実行してみたいと思います。
# /usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
OK - load average: 0.07, 0.05, 0.01|load1=0.070;15.000;30.000;0; load5=0.050;10.000;25.000;0; load15=0.010;5.000;20.000;0;
のようにノード内で実行すると結果が帰ってきました。
※ロードアベレージが上がりすぎていないかの監視です
NRPEサービスの開始
まず、nrpeの設定ファイルを編集し、NagiosサーバのIPアドレスを追加しておきます。
# vi /etc/nagios/nrpe.cfg
---allowed_hostsのところを探し、以下の行を追加します。
allowed_hosts=[NagiosサーバのIPアドレス]
また、先ほどインストールしたNagiosプラグインでの監視の定義を書いておきます。
command[check_load]=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
が最初から書いてありましたが、以下の四つも追加することにします。
※あらかじめ1-2で行ったテストを実行しておきます。
command[check_disk1]=/usr/lib/nagios/plugins/check_disk -w 20 -c 10 -p /
command[check_disk2]=/usr/lib/nagios/plugins/check_disk -w 20 -c 10 -p /home
command[check_ntp]=/usr/lib/nagios/plugins/check_ntp -H 210.188.224.14 -w 1 -c 2
command[check_swap]=/usr/lib/nagios/plugins/check_swap -w 90% -c 50%
---
nrpeを再起動し
# service nrpe start
サーバ起動時に立ち上げるようにする
# chkconfig nrpe on
これで、/etc/nagios/nrpe.cfgに書かれている監視がNagiosサーバからできるようになります。
Nagiosサーバでの設定
インストール
サーバ側にcheck_nrpeプラグインをインストールする
# yum install nagios-plugins-nrpe
Nagiosサーバからのテスト
$ /usr/lib/nagios/plugins/check_nrpe -H [ノードのIPアドレス] -c check_load
OK - load average: 0.00, 0.00, 0.00|load1=0.000;15.000;30.000;0; load5=0.000;10.000;25.000;0; load15=0.000;5.000;20.000;0;
のようにOKが返ってくれば通信成功です。外部からロードアベレージができるようになりました。
他のcheck_user,check_disk1…も全て確認しておきます。
NRPEの定義
# cd /usr/local/nagios/etc/objects
# vi commands.cfg
---以下の行を追記
# 'check_nrpe' command definition
define command{
command_name check_nrpe
☆check_nrpeがあるパスを書く
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
---
設定ファイル&再読み込み
先ほど作ったtest_node.cfgファイルにnrpeでの監視定義も追記します。
# cd /usr/local/nagios/etc/servers
今回テスト的に設定する監視対象のファイル
# vi test_node.cfg
---NRPEの監視定義を行末に追加
define service{
use server-test-service
host_name testnode.jp
service_description check_load
check_command check_nrpe!check_load
}
define service{
use server-test-service
host_name testnode.jp
service_description check_disk1
check_command check_nrpe!check_disk1
}
define service{
use server-test-service
host_name testnode.jp
service_description check_disk2
check_command check_nrpe!check_disk2
}
define service{
use server-test-service
host_name testnode.jp
service_description check_ntp
check_command check_nrpe!check_ntp
}
define service{
use server-test-service
host_name testnode.jp
service_description check_swap
check_command check_nrpe!check_swap
}
---
設定ファイルに不整合がないかテスト
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
出力されたものを確認して問題無ければnagiosサーバを再起動します。
# service nagios restart
内部からでないと監視できないリソースもNagiosサーバで監視できるようになりました。
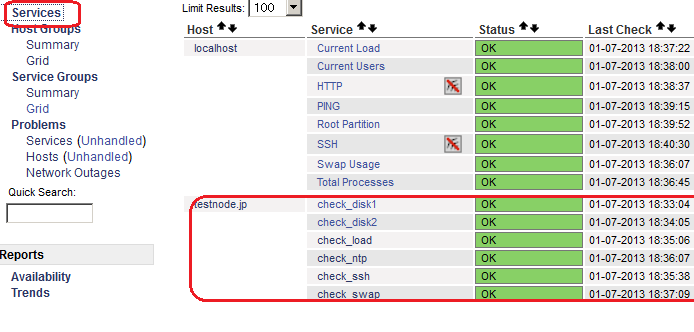
設定ファイルに関して
この後、今回編集した設定ファイルをいじって通知先を変更したり、追加で監視項目を追加していったりしてより強固な監視にしていきます。
Nagiosの設定はテンプレート的に汎用的な定義を作っておいてそれを継承する、という設定のやり方が基本になっています。 ※設定ファイルの中にuseというのが頻出しますが、このuseでテンプレート的な定義を継承しています。 use ~たどっていくと「generic-service」というものが元になっています。このgeneric-serviceはtemplates.cfg の中に設定されています。こちらが、これらに監視の細かい設定がされています。
弊社でも日々監視対象が増えておりますので監視設定の見直し(継承とグループ化をうまく使えば効率よく設定でき、設定漏れも防げる)を少しづつ進めながら運用しています。
関連記事
PICK UP
-

タグ: AIエージェント, GA4, Gemini Enterprise, Google Cloud, Google アナリティクス, ai, コラム
Gemini Enterpriseの企業導入法を解説。エージェント環境づくりと活用事例 -

タグ: ITreview, SaaS, The Best Software by Category, The Best Software in Japan 2026, shutto翻訳, ウェブサイト翻訳ツール, コラム
ITreview The Best Software by Category 2026を受賞しました! -

タグ: AI議事録, コラム, ナレッジ共有, 会議効率化, 文字起こし, 業務効率化, 生成AI活用, 生産性向上, 社内DX
【オープン社内報 2026年7月号】イー・エージェンシーグループ プレミアムニュース -

タグ: エンジニア採用, キャリア採用, コミュニケーション, コラム, ブログ, リモートワーク, ワーケーション, 採用情報, 文化, 環境
日本全国からの応募をお待ちしております! 2026年7月の募集職種一覧!ビジネス職を中心に採用強化中! -

タグ: CART RECOVERY, カゴ落ち対策, カートリカバリー, クラウドサービス, コラム, ニュース
【メディア掲載】読売新聞にて『CART RECOVERY®(カートリカバリー)』の調査データが紹介されました -

タグ: MAツール, コラム, システム比較, マーケティングオートメーション, メールマーケティング, メール到達率, メール配信, メール配信サービス, メール配信システム, メール配信ツール
【2026年最新版】中小企業向けメール配信システムの正しい選び方!初心者でも失敗しない5つの選定基準を網羅解説


